
Sanskrt a čeština
V anglických textech o józe se to pojmy ze sanskrtu jen hemží. Když je pak chceme použít v češtině, tak narážíme na celou řadu nejasností: je tady správně „y“ nebo „j“? Proč tu někdo píše dlouhé „á“ a někdo ne? Apod. V tomto článku se podíváme právě na to, jak sanskrt do češtiny přepisovat správně, proč se píše „aštánga“ a ne „aštanga“, proč je „ásana“ a ne „asána“ a proč se píše „mudra“, i když by „mudrá“ bylo přesnější.

Poznámka: Transliterace a transkripce
Při přepisu sanskrtu do češtiny je dobré rozlišovat dva pojmy: transliterace a transkripce:
- transliterace: přesný přepis, kdy jednomu písmenu odpovídá právě jen jedno písmeno v cílovém jazyce. Ze sanskrtu se většinou k transliteraci používá mezinárodní standard IAST, viz dále.
- transkripce: spíše fonetický přepis. Text se čte stejně, ale může být napsán jinak.
Tyto dva pojmy se tu a tam objeví dále v textu, a proto jsem je zde chtěl na začátek uvést. Pokud mluvím o přepisu, jde o transkripci.
Čeština se hodí k sanskrtu
Sanskrt je indo-evropský jazyk a má proto stejné kořeny jako část evropských jazyků, obzvláště pak jazyky slovanské. Porovnejme např. sanskrtská slova mátr (मातृ), bhrátr (भ्रातृ) s českým matka a bratr. Podobně i slovo véda (वेद) má stejné kořeny jako česká věda. Toto příbuzenství má pro nás jednu velikou výhodu – čeština je velice vhodná pro přepis sanskrtu. Např. angličtina má úplně jiné fonémy („zvuky písmen“) a nedovede sanskrt dobře přepsat. Autoři často musí volit komplikované varianty, aby to alespoň trochu znělo jako v originále (a ve většině případů stejně musí rezignovat na délku samohlásek). Z toho důvodu mnoho autorů, kteří se snaží sanskrtské výrazy z angličtiny přepsat do češtiny, naráží na neřešitelné problémy a vznikají tak často nesmysly.
Výslovnost češtiny a výslovnost sanskrtu jsou si velmi blízké, a proto můžeme velice snadno a zároveň velice přesně přepisovat výrazy ze sanskrtu. Pokud byste normálnímu Čechovi dali stránku textu v sanskrtu přepsanou do češtiny, tak je schopen ji bez problémů přečíst tak, že mu Ind znalý sanskrtu bude rozumět (nebude to asi vždy čisté, ale rozumět mu bude).
Co se píše, to se čte
Sanskrt má jednu velikou výhodu: čte se přesně tak, jak se píše. To je velmi podobné češtině. My třeba trochu měníme zvuk písmen: z „d“ se stane „ď“, pokud je po něm „i“ nebo „ě“ apod. Sanskrt se snaží o naprosto přesné zaznamenání zvuků písmem. Jednomu písmenu prostě odpovídá jeden zvuk bez ohledu na ostatní písmena.1
To znamená, že přepis sanskrtu do češtiny je docela snadný a zároveň, že přepis sanskrtu do angličtiny, francouzštiny nebo němčiny je komplikovaný (a přepis sanskrtu z angličtiny, francouzštiny či němčiny do češtiny je nemožný).
Dlouhé a krátké samohlásky
Jedním z důležitých prvků, které angličtina nemá při přepisu k dispozici, ale čeština ano, je volba dlouhé nebo krátké samohlásky. V sanskrtu jsou totiž důležité a špatné umístění délky může snadno změnit význam. Např. šála (शाला) znamená místnost, ale šala (शल) je hůl nebo kopí.
Tady je v češtině jedna záludnost: většina slov má přízvuk vázaný na první slabiku a máme tendenci toto pravidlo uplatňovat i na slova ze sanskrtu. Proto nám dobře zní třeba jogín nebo asána, ale správně je jógin (योगिन्) a ásana (आसन). I když už bylo slovo „jogín“ uznáno za správně, tak bych se mu radši vyhnul. Není totiž dost dobře možné přepisovat všechna slova ze sanskrtu správně a jedno špatně jen díky tomu, že to ve slabé chvilce povolil Ústav pro jazyk český.
IAST
Pro přepis sanskrtu existuje mezinárodní standard. Označuje se jako IAST, což znamená „International Alphabet of Sanskrit Transliteration“ neboli „Mezinárodní abeceda pro transliteraci sanskrtu“. Často se s ní můžete setkat v anglických knížkách, které chtějí používat co nejpřesnější přepis (transliteraci). Každé písmeno ze sanskrtu zde má vlastní písmeno z latinky. Protože latinka má méně písmen, tak jsou k nim připojovány různé značky (tečky pod nebo nad písmeny apod.). Věta přepsaná v IAST vypadá např. takto „yogaś-citta vṛtti nirodhaḥ ॥ tadā draṣṭuḥ svarūpe’vasthānam ॥“. Můžeme vidět, že snadno rozpoznáme dlouhé a krátké samohlásky díky „čárce“. Většina znaků se pak čte jako v angličtině (tj. „y“ je „j“ apod.). Nechci tento přepis nyní rozebírat, tak jen upozorním na pár chytáků:
- „c“ se zde čte vždy jako „č“
- „ṣ“ i „ś“ jsou „š“
- „e“ i „o“ jsou „é“ a „ó“. Sanskrt totiž nemá krátké „e“ a krátké „o“, proto se nad nimi nedělá v IAST čárka.
Sandhi
Když se podíváme v originále na druhý verš z Jóga súter, který jsem citoval výše, tak bude vypadat nějak takhle: „yogaścittavṛttinirodhaḥ“. Celá věta je spojená do jednoho slova. Sanskrt má tendenci spojovat slova a existuje pro to celá řada pravidel. Těm se říká pravidla sandhi (संधि, doslova „spojení“). Pokud například jedno slovo končí na „a“ a hned za ním další slovo začíná na „a“, tak se spojí dohromady z těchto dvou „a“ vznikne „á“ (a+a=á). Například ašta (osm) + anga (část) = aštánga. Nebo a+u=ó, takže mundaka + upanišad = munadkópanišad. Některá pravidla jsou o něco složitější například yogaścitta je spojení yogaḥ + citta. Závěrečné „ḥ“ se zde změní v „ś“. Těchto pravidel je docela dost a ze začátku působí velmi komplikovaně. Není potřeba se je učit. Spíš je důležité vědět, že existují a že se s nimi můžete v jógových termínech setkat. Pokud by někoho zajímala podrobněji, tak je detailně najdete v každé učebnici sanskrtu.
Odbočka: sandhi v češtině
Sandhi se vyskytuje i v jiných jazycích než v sanskrtu. Pozůstatky podobného pravidla najdeme i v češtině. Říkáme, že někdo někoho „vede“, ale infinitiv je „vésti“. Je to od praslovanského kořene „ved“, kde se „d“ změní na „s“ po přidání „ti“.
Kořeny a nominativ
Pokud máme text v češtině nebo v angličtině a používáme v něm pojmy ze sanskrtu, tak se podstatná jména zpravidla používají v podobě kořene (tj. to, co najdeme ve slovníku). Proto se v odborné literatuře mluví o „karmanovém zákonu“, protože karman (कर्मन्) je slovníkový tvar. Mnoha lidem to zní přeci jen trochu divně. „Karma“ je pro nás známější pojem než „karman“, i když oba znamenají totéž. Karma (कर्म) je totiž nominativ singuláru2 od karman. Hodně autorů (hlavně v angličtině) preferuje při transkripci používání nom. sg. místo slovníkového tvaru – anebo alespoň používají tvar nom. sg. u slov, kde se to vžilo, protože kořenový tvar zní někdy zvláštně: srovnej kořen rádžan (राजन्, král) a nom. sg. rádža (राजा). Můžete se proto setkat s oběma způsoby přepisu. Teoreticky správnější je používání kořene, ale jsou dobré důvody i pro použití tvaru v nom. sg.
Na konec „á“
Při transkripci sanskrtu do češtiny se uplatňuje zvláštní pravidlo, které mění původní originál. Pokud slovo končí na dlouhé „á“, přepíše se jako krátké „a“. Proto např. mudrá (मुद्रा) se přepisuje jako mudra. Je to kvůli tomu, že v českém textu potřebujeme tato slova skloňovat, a to by s dlouhým „á“ nešlo. Toto pravidlo tvoří pro češtinu největší rozdíl mezi transkripcí a transliterací.
Jak tedy přepisovat?
Pokud se nechcete přímo naučit sanskrt, ale přitom byste neradi tento jazyk masakrovali špatným přepisem, tak je asi nejsnazší tento postup:
- Najděte hledané slovo v IAST. Většina jógových termínů má tento přepis třeba na wikipedii. Např.:
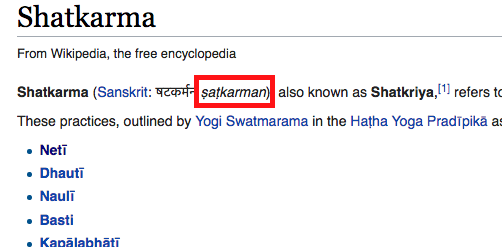
- Zapamatujte si:
- c = č
- ṣ / ś = š
- e / o = é / ó
- y = j
- j = dž
- ñ = ň
- ṃ = n
- zbytek písmen s tečkami nad nebo písmeny přepište jako by tam tečky nebyly.
- Pokud slovo končí na dlouhé „á“, změňte ho na „a“.
- Výsledek by v tomto příkladu vypadal takto: „šatkarman“.
Wikipedie je bohužel nespolehlivá a občas se i zde objeví chyby v IAST. Ideální je sehnat si třeba nějaký tištěný slovník jógových pojmů. Mně se osvědčil: Yoga Kośa (Kaivalyadhama S.M.Y.M. Samiti, nové rozšířené vydání 2009. ISBN 81-89485-29-6). Takhle vypadá z vnějšku a zevnitř:


Jsou tam snad všechny termíny, na které v souvislosti s jógou můžete narazit a díky IAST přepisu je pak můžete snadno převést do češtiny.
Na závěr pár otázek a odpovědí
Otázka: A proč by mě měl správný přepis vůbec zajímat? Copak to není jedno?
Není. Správný přepis je jako správné dodržování gramatiky. Můžete napsat text plný gramatických chyb, a i když bude jeho obsah úžasný, tak to bude hodně snižovat jeho hodnotu a důvěryhodnost (a čitelnost). Navíc je sanskrt jedním z nejstarších psaných jazyků na světě, je to jazyk drtivé většiny posvátných jógových textů a všech jógových odborných pojmů a tím pádem si trochu úcty snad zaslouží. To nejmenší, co můžeme z úcty k tradici jógy udělat, je nemasakrovat její jazyk.
Otázka: Tohle je nějaký složitý. Proč nemůžu prostě používat anglický přepis? Co je špatného na ashtanga nebo yoga?
Teoreticky samozřejmě můžete používat anglický přepis. Samo o sobě na něm není nic špatného. Ovšem je třeba ho dodržet v celém textu. Nelze např. napsat „ashtanga jóga“ nebo mluvit o „vishuddha čakře“ apod. Zároveň je dobré na to upozornit i čtenáře. Pokud se v oblasti jógy nepohybují, tak nemusí poznat, že by měli něco číst anglicky. Setkal jsem se s několika lidmi, kteří následkem takovýchto textů označovali „džálandhara bandhu“ za „jálandhara bandhu“ apod.
Správný přepis sanskrtu usnadňuje čtenářům četbu a zároveň jim umožňuje správně sanskrt vyslovovat. Pokud praktikujete ásany v tradici Pattabhiho Joise, tak si vzpomeňte, jak se na začátku recituje mantra – prakticky všichni ji masakrují, protože nevědí, kde je dlouhá a krátká samohláska. Není to ovšem jejich chyba – je to tím, že mají mantru jen v anglickém přepisu (tady si rovnou udělám reklamu na svůj překlad a přepis Úvodní a závěrečné mantry 🙂 )
Otázka: Funguje tenhle přepis i pro delší texty jako jsou třeba mantry?
Úplně ne. Toto je standardní přepis pro sanskrtské pojmy v rámci českého textu. Pokud chcete recitovat mantry, většinou jde o přesnou výslovnost a tam je už potřeba použít několik dalších znaků. Také musíme rozlišovat „á“ a „a“ na konci slov, takže není možné psát vždy krátké „a“ jako při přepisu do češtiny.
Já pro přepis manter (viz třeba Tahák na recitaci manter) používám svou verzi fonetického přepisu + nechávám originál pro znalce.
Otázka: Jsou nějaké obzvlášť problematické pojmy, které angličtina přepisuje hodně jinak?
Je jich celá řada. Velkou část z nich tvoří místopisné názvy. Angličané Indům moc nerozuměli, a tak místní názvy vesměs vyslovovali, tak že to originál pouze připomínalo (viz Mysore a Maisúru, Delhi a Dillí3 a aby za všechno nemohli Britové, tak třeba Portugalci překřtili Mumbaí na Bombaj4 atd. Protože se mnoho takových slov používalo v angličtině doslova staletí, tak se i nyní běžně užívají, i když je jejich přepis špatný. Kromě místopisných názvů je to třeba: brahmin (správně: bráhmana ब्राह्मण), gnyana (správně: džňána ज्ञान), Patanjali (správně: Pataňdžali पतञ्जलि).
Další kategorie zmatků přidal přepis sanskrtských slov ve výslovnosti novoindických jazyků – šarvángásana (správně: sarvángásana सर्वाङ्गासन) nebo sauča (správně: šauča शौच). Hindština (a některé další severoindické jazyky) má tendenci změkčovat, naproti tomu jihoindické jazyky mají obecně tendenci zostřovat. Ne všichni Indové umí sanskrt, a proto mají tendenci sanskrt vyslovovat podle svého rodného jazyka.
Otázka: Setkal jsem se s tím, že se psala „ásanam“ místo „ásana“. Proč?
To „m“ na konci je pádová koncovka pro nominativ singuláru. Do češtiny je správně „ásana“.
Otázka: Někdy se říká „súrjanamaskár“ a někdy „súrjanamaskára“. Co je správně?
V sanskrtu je správně súrjanamaskára. Ovšem většina novoindických jazyků vypouští závěrečné „a“ a vyslovují „namaskár“. Toto slovo je nesmírně časté – můžete ho říci i místo pozdravu. Proto ho člověk slyší pořád. Pro Indy je pak přirozenější říci „súrjanamaskár“ a to od nich oposlouchali lidi ze západu, a proto se teď hodně říká „súrjanamaskár“. Pokud to tak budete číst, tak to asi ničemu nevadí, ale v psaném textu by se ze sanskrtu mělo přepisovat i závěrečné „a“ – takže súrjanamaskára.
Otázka: Slyšel jsem, že by se slova ze sanskrtu měla v češtině skloňovat podle stejného rodu jako mají v sanskrtu. Je to tak?
Částečně to tak dřív bylo. Jóga je v sanskrtu například mužského rodu, a proto se ještě za první republiky nemluvilo o „józe“ ale o „jógu“. Ale tento přístup nejde v češtině udržet a dnes se většinou daná slova v češtině skloňují podle své koncovky.
Poznámky
- Ovšem také se to nepodařilo na 100%. Např. ज्ञान by se mělo číst džňána, ale většina sanskrtu znalých Indů to čte dňána. Také अः se na konci řádku čte „aha“, ale uprostřed věty je to „ah“ apod.
- Možná vás napadne otázka: „Proč proboha používá tyhle latinské názvy pádů? Asi se chce vytahovat, jak je chytrej.“ To je pravda, ale hlavní důvod je ten, že sanskrt má už pár tisíc let rozpracovanou gramatiku a má jinak seřazené pády než latina. Např. akuzativ, který je u nás čtvrtý pád je v sanskrtu druhý apod. Protože by v tom pak byl chaos, tak se používají výhradně latinské názvy pádů (a fajnšmekři používají sanskrtské názvy).
- दिल्ली v hindštině.
- Zajímavé je, že k tomu podle všeho nevedlo zkomolení, ale portugalské bom baim znamená „malý dobrý přístav“.


Také by vás mohlo zajímat

Ganéš čaturthí

PC hra: „The Durga Puja Mystery“
